Part 1: A Simple Reduction
Most of us agree - science is good 1.
But we don’t agree on what science is. To some, it’s identically the scientific method. To others, its a general vibe of asking questions of the real world 2. This leads to frustrating conversations 3.
In this post, I want to tell you briefly about how I define ‘science’. I’ll show you the system that I use in any scientific question, then walk through what I see as the process of science. We’ll end with a brief statement about why this matters and a bigger implication for how we should do medicine-adjacent science.
What Is Science
We need to start our discussion with a system diagram - an explicit representation of what we think we’re studying and its ambient space 4.
Our System
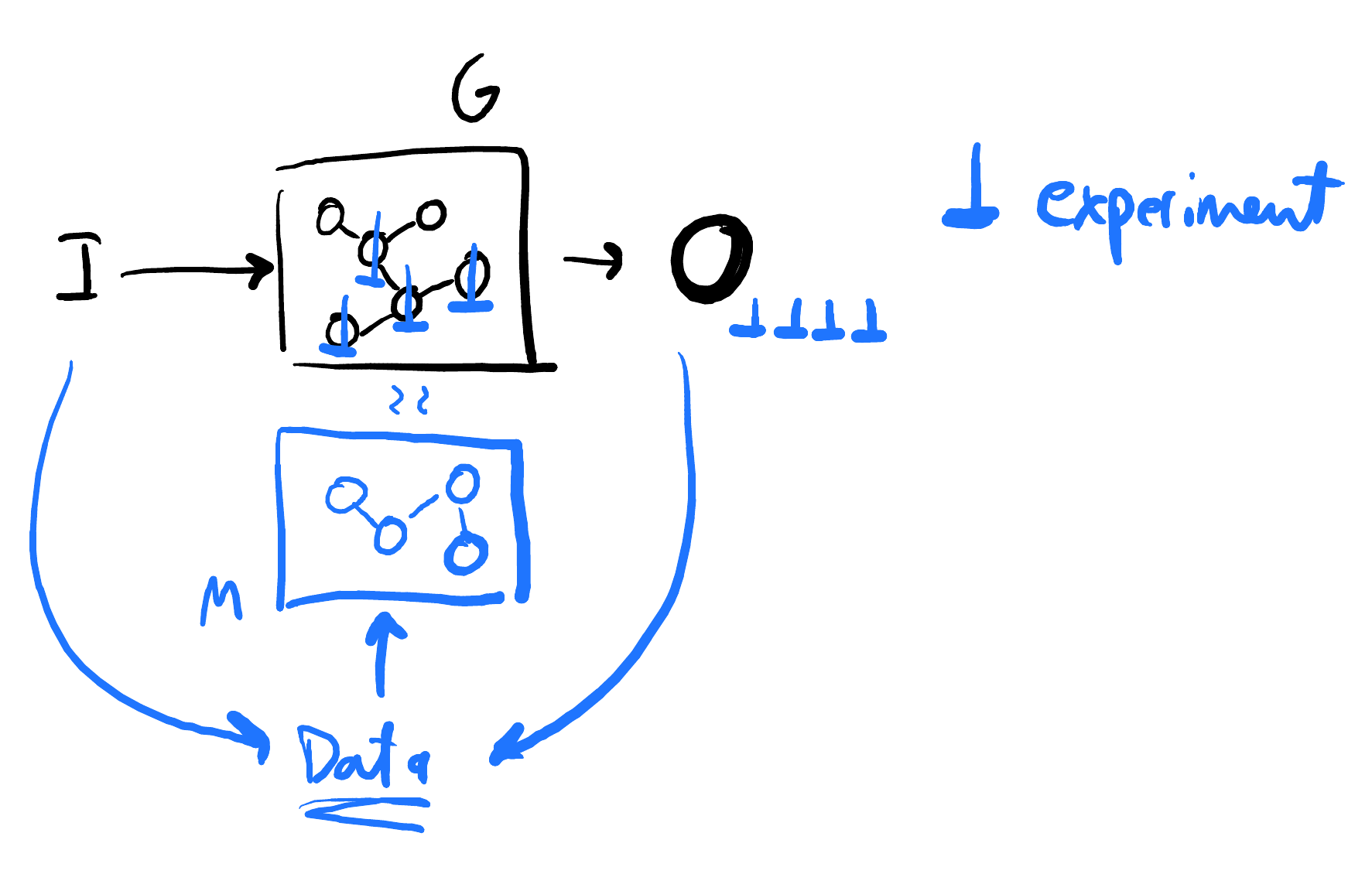 |
|---|
| A system diagram for a generic generator and how experiments + data + models (M) emerge around it. |
Generators and Experiments
A generator is any phenomenon we’re interested in understanding. It transforms some input into some output, and we’re interested in understanding the rules of that transformation 5. Like “how does a leaf convert water and sunlight into energy?” or “How does a bacteria’s cell wall form?”.
The generator often has many moving parts, especially when it’s out in the wild. Experiments can come in and help freeze some of those moving parts, letting us better determine whether the other parts directly relate to each other. Experiments also give us the chance to measure things very well - so we can be even more sure that our observations reflect the generator and not something else getting tangled in.
Building Models of Generators
The generator out in the real world isn’t something we can see, smell, or touch directly - it’s too far. But we need to be able to feel some familiarity with it, have some idea of how things move when other things move. This is what I’ll call “understanding”, and it takes the form of a model, on paper, that looks as similar to the real relatonships of the generator as possible.
Data Tightens Guarantees
Observations that are quantitative and structured in some way become data, and data becomes a powerful tool to guide how we build our model of the generator. Data comes in and tells us what our model must account for. Because the data came from the generator, and our model can’t be congruent to the generator if it can’t also yield that data.
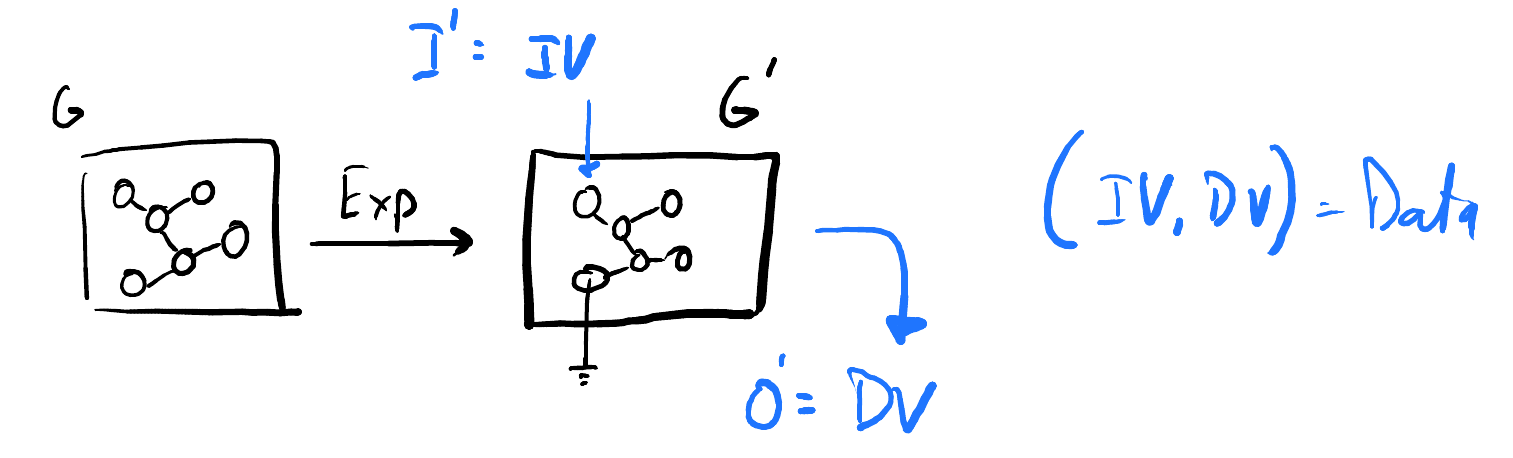 |
|---|
| *Experiments fix parts of our generator so we can more directly ascribe movement in the output to movement in our input. This gives us the classic IV/DV framework, the pairing of which gets us classical data. |
But, perhaps surprisingly, you don’t actually need data to build a model of a generator. You can, in theory, improve a model solely by reasoning through looser observations or, indeed, axioms of the broader world. A great example of this is the 1919 eclipse which confirmed Einstein’s pre-data model.
Science is a Process
So we’ve seen that there’s a generator and our model of that generator - and we see that data tells us what our model needs to be able to align with. Science is the process of building a model that is congruent with the generator. In other words, science itself is engineering a model with the goal of being congruent with the unseen insides of a real world generator.
Iteratively Reducing Distance
There’s a “distance” between our model and the generator. This “distance” needs to be brought to zero, if you’re a die-hard scientist. But, in the real world, we’ll always have noise (both epistemic and measurement), so we’re trying to bring this distance down to something reasonable 6.
The distance is tough to ascribe a concrete number to in the real world since we don’t know what the generator truly looks like 7. But we can assess it qualitative by things like prediction and, most important to engineering, perturbation. Our model needs to be able to behave in the same way to weird input changes as the generator does.
We achieve this iteratively, by steadily making our models better and better. There are different ways to iterate - eg characterizing each part perfectly before moving to the next versus quickly developing first-order models of all parts, then refining to higher orderall together. But iteration is still key, and something that should be embraced more fully.
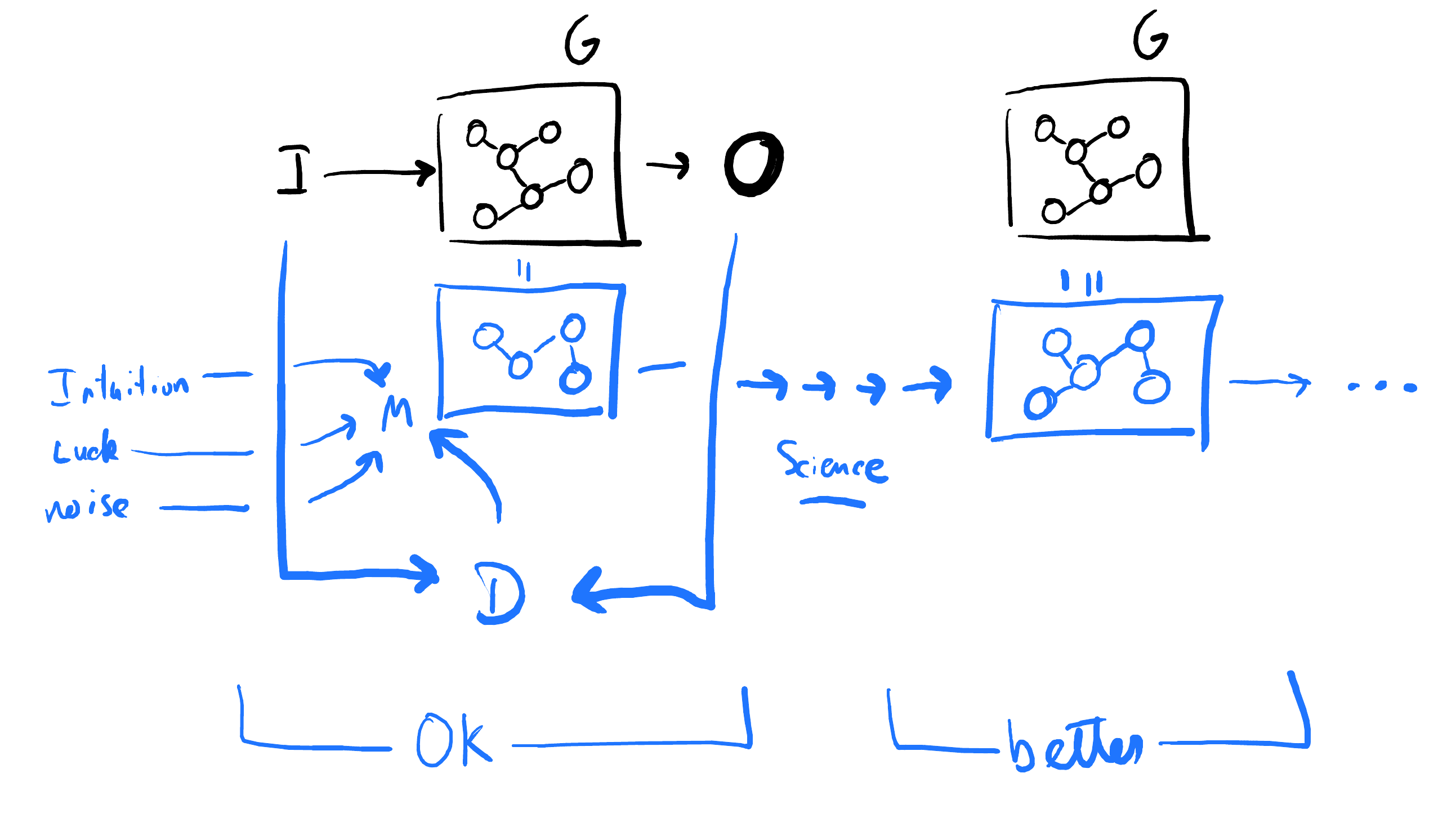 |
|---|
| Science involves iteration - of building a model that is almost-definitely not going to look like our Generator, then steadily modifying it until it converges. Convergence is tough to assess, but prediction plays a key role. Data is a key part of this, but so are many other things |
Final Words
Science is a process of building a model, on paper, that is congruent with a generator, or real world phenomenon. Data and experiments have a powerful role to play, but they are neither necessary nor sufficient to do science. What is absolutely necessary: a model and principled ways to update it.
Why is this important? Because, in this definition, engineers and medical doctors also do science even though their first priority is intervention. They don’t do clean experiments, isolating variables and perfectly measuring subparts - and yet they’re building up a model that achieves some congruence with the generator. They do this through multidimensional reasoning and direct, empirical intervention that is unavoidable.
It’s far from perfect, but it serves as a powerful complement to experiment-based and/or reductionist science. We’ll talk much more about this in a subsequent post.
That being said, there are some good arguments that science, the enterprise, is bad actually. These mostly revolve around the unsustainable ways we do science, and whether it’s even possible to do science in a non-exploitative way. A topic for another day… ↩︎
To a small few, it’s that specific Journal with cool pictures in the Dentist’s office or that startup with a grandoise name. Semantic pollution is a real problem, and we’ll talk about it later. ↩︎
One reason I have so much to say about this topic is that I constantly found myself having frustrating conversations during my MD/PhD. I’d be talking to a scientist, who thinks only narrow, rigorous experimentation leads to scientific inferences. Then a clinician, to whom “science” is just whatever is published in NEJM/Nature. Then I’d talk to the engineer who, imho, had the most useful definition of science, and one that the others would love also. But because everyone was conflating all the different “science"s and there’s always a tendence to disparage anything outside of a given field’s narrow dogma, everyone just decided to avoid defining it and moving forward with pleasant fiction. But there is a better way. ↩︎
System Diagrams are critical tools in any scientific problem, imho. They force us to really (a) think about the thing we’re studying and how/why we’re drawing its boundaries with respect to its context, and (b) align on our definition of the setup, before diving into the inference itself. I’ll talk more about ↩︎
Prediction is a part of understanding, but it’s just one of many. Perturbative prediction is, imho, more important - not only can you predict how inputs go to outputs, you can predict how inputs go to outputs as all the other variables are changing too. That part is hard. The final part of understanding is control - the ability to deliberately evoke an input$\rightarrow$output mapping. ↩︎
There is no simple answer to “reasonable” - it depends on the task at hand, the cost of errors, etc. So we’ll need to cover the concept of a “pullback” soon to be able to better identify a reasonable distance to achieve. ↩︎
We don’t need a hard number to compare “closer” and “further” though - and that’s the approach that leads to the best science. In a way, we’re triangulating to the truth by trying to always get closer - regardless of how close we “actually are”. ↩︎